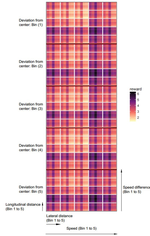
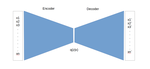
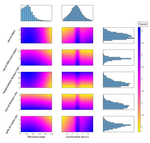
Accurate modeling of bicycles in microsimulation tools is challenging due to the limited availability of detailed data, complexity of cyclist decision-making, and heterogeneity in cycling behavior. This paper proposes an agent-based bicycle simulation method in which generative adversarial imitation learning (GAIL) is used to infer the uncertain intentions and heterogeneous preferences of cyclists from observational data. The model is tested on videoderived data of cyclists on a unidirectional path in Vancouver, Canada. In cross-validation, multivariate distributions of movement variables such as speed, direction, and spacing are similar between observed and simulated cyclist trajectories. The model also performs well in comparison to two other cyclist simulation models from the literature. The proposed approach to agentbased microsimulation is a significant advancement, with continuous, non-linear, and stochastic representation of cyclist states, decisions, and actions. The enhanced consideration of cyclist diversity is necessary for developing bicycle networks for all ages and abilities of riders.