Toward agent-based microsimulation of cyclist following behavior: Estimation of reward function parameters using inverse reinforcement learning
Abstract
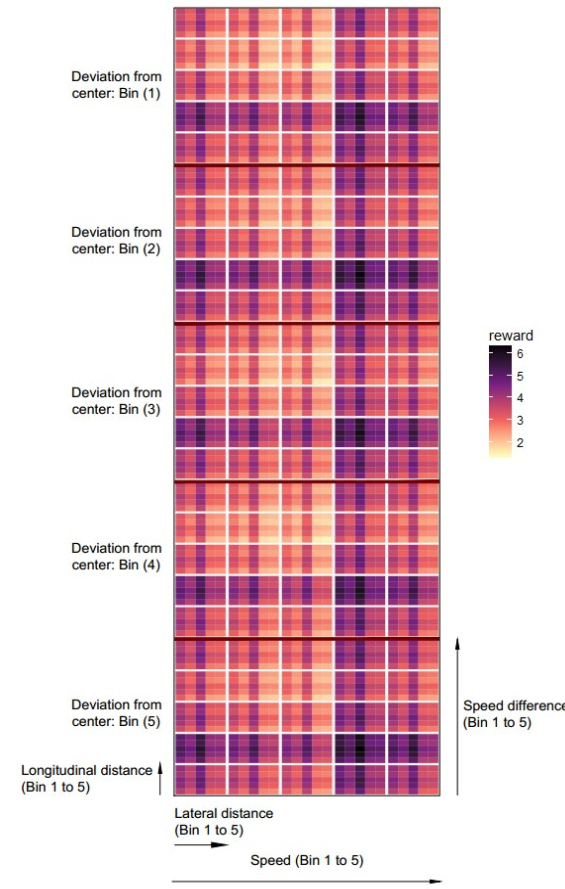
Reward functions are a key component in developing agent-based microsimulation models. The objective of this research is to estimate reward function parameters for cyclists in following interactions with other cyclists on bicycle paths. Decisions of cyclists (acceleration and direction) in following interactions are modeled as a finite state Markov Decision Process, in which the reward function describing the desired state of the cyclist is unknown. Two algorithms of imitation learning using Inverse Reinforcement Learning (IRL) are evaluated to estimate reward function parameters: Feature Matching (FM) and Maximum Entropy (ME) IRL. The algorithms are trained on 1297 cyclist trajectories in following interactions extracted from video data using computer vision, and then validated using a separate set of 349 trajectories. The estimated reward function parameters indicate how cyclists weigh the five state features in the reward function: speed, speed difference from leading cyclist, lateral position in path, lateral distance from leading cyclist, and longitudinal distance from leading cyclist. Following cyclists tend to prefer intermediate values of longitudinal and lateral distance to leading cyclists. Cyclists also prefer high speeds, with low speed difference from the leading cyclist and low deviation from the center of the path. Implementation of the reward functions derived from the FM and ME algorithms correctly predicted 58% and 67%, respectively, of the observed cyclist decisions (acceleration and direction) in the validation data set. This research is a key step toward developing operational bicycle traffic microsimulation models with applications such as facility planning and bicycle safety modeling.
Hossameldin Mohammed
Senior Machine Learning Engineer
My research interests include traffic safety, traffic simulation, transportation demand modeling, generative machine learning, imitation learning, deep learning and experimental design.