Inferring Nonlinear Reward Functions for Cyclists in Following Interactions Using Continuous Inverse Reinforcement Learning
Abstract
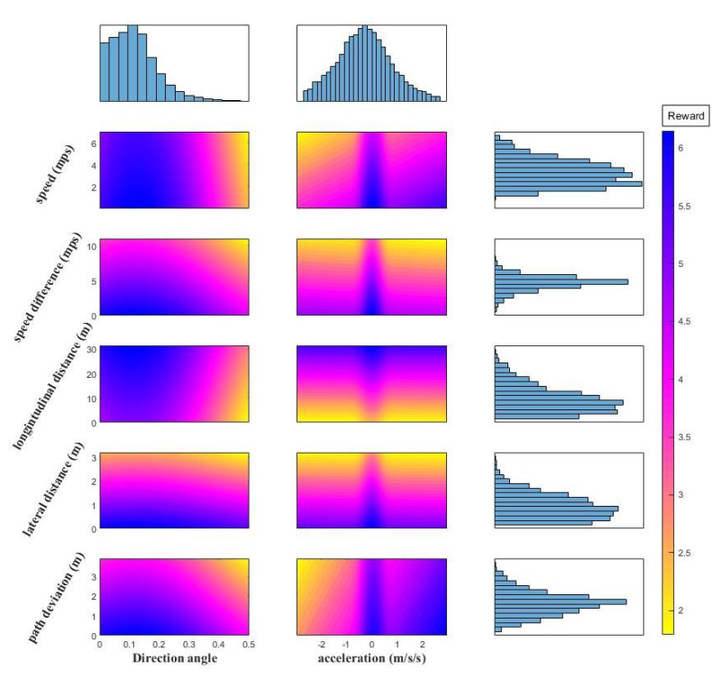
Understanding and modeling cyclist movement patterns is an essential step in developing agent- based microsimulation models. The aim of this study is to infer how cyclists in following interactions weigh different state features, such as relative distances and speeds, when making guidance decisions. Cyclist guidance decisions are modeled as a continuous state and action Markov Decision Process (MPD). Two Inverse Reinforcement Learning (IRL) algorithms are evaluated to estimate the MPD reward function in a linear form based on Maximum Entropy (ME) and in a nonlinear form based on Gaussian Processes (GP). The algorithms are trained on 856 cyclist trajectories in following interactions extracted from video data using computer vision, and then validated using a separate set of 172 trajectories. The estimated reward functions imply cyclist preferences for low lateral distances, path deviations, speed differences, accelerations and direction angles, but high longitudinal distances from leading cyclists. The mean and variance of the reward function learned using GP can be applied to simulate heterogeneous cyclist preferences and behavior. Predicted trajectories based on Q-learning with the linear and non-linear reward functions are compared to the validation data. This research is a fundamental step toward developing operational bicycle traffic microsimulation models with applications such as facility planning and bicycle safety modeling. Key novel aspects are the investigation of continuous, non- linear, and stochastic reward functions for cyclist agents using real-world observational data.
Hossameldin Mohammed
Senior Machine Learning Engineer
My research interests include traffic safety, traffic simulation, transportation demand modeling, generative machine learning, imitation learning, deep learning and experimental design.